
Ten kurs został także nagrany w wersji wideo (powyżej). Wersja tekstowa jest dostępna w poniższym artykule:
HTTP to skrót od „Hypertext Transfer Protocol”. Komunikacja HTTP realizowana jest poprzez wysłanie żądania (ang. request) przez klienta do serwera, który generuje odpowiedź (ang. response).
Brzmi niezrozumiale? Każdy z nas robi to dziesiątki razy dziennie, gdy po prostu przegląda strony internetowe. Za każdym razem, gdy otwierasz przeglądarkę i przeglądasz jakąkolwiek stronę WWW, lub np. wysyłasz formularz kontaktowy, bierzesz udział we wspomnianym wyżej cyklu request-response.
Posłużmy się przykładem, by lepiej zobrazować powyższe zdanie. Poniżej znajduje się grafika, która w uproszczony sposób obrazuje komunikację HTTP na przykładzie wejścia na dowolną stronę WWW w przeglądarce:
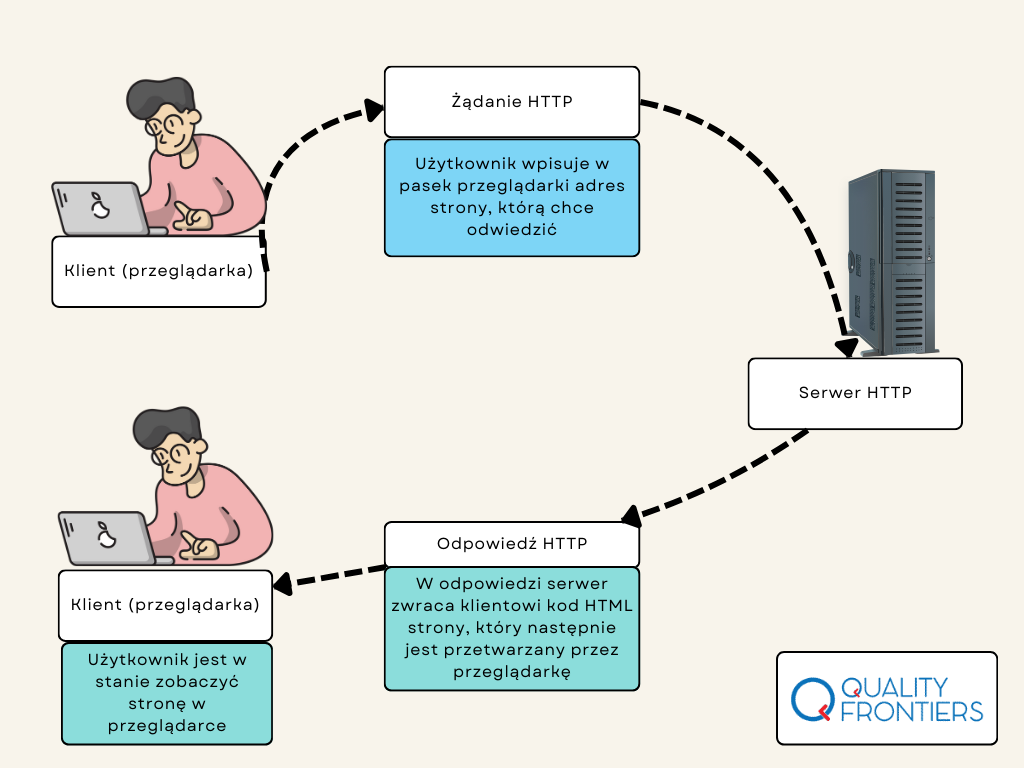
Do pełnego zrozumienia komunikacji HTTP musisz poznać kilka pojęć. W poniższych akapitach opisane zostały najważniejsze z nich. Na pierwszy ogień idą…
Metody HTTP
Każde żądanie wysyłane do serwera w protokole HTTP może być przekazywane przy użyciu różnych metod (ang. methods), które określają typ operacji, jaką klient chce wykonać na zasobach serwera. Może to być pobranie zasobu, przesyłanie danych, ich aktualizacja, itd.
Najpopularniejsze metody HTTP to:
- GET – pobieranie danych. Często stosowana na przykład do pobierania zawartości stron internetowych.
- POST – wysyłanie danych do serwera (tworzenie nowych danych). Często używana np. do przesyłania danych z formularzy internetowych, bądź do przetwarzania płatności.
- PUT – aktualizuje zasób na serwerze.
- PATCH – modyfikuje część zasobu.
- DELETE – usuwa zasób z serwera.
Nagłówki
Nagłówki HTTP to część każdej komunikacji między klientem (np. przeglądarką internetową) a serwerem. Są to parametry, które przesyłane są razem z samą zawartością żądania lub odpowiedzi. Najłatwiej jest je porównać do informacji dodatkowych na kopercie listu: chociaż zawartość listu jest najważniejsza, dodatkowe informacje mówią nam o tym, jaki jest adres nadawcy, adres odbiorcy, a czasem także jaki jest sposób przesyłki. Podobną rolę pełnią nagłówki HTTP.
Nagłówki żądania
Wysyłane przez klienta, informują serwer o tym, co klient chce zrobić lub otrzymać. Najpopularniejsze nagłówki żądania to:
| Nagłówek | Opis działania | Przykład |
|---|---|---|
Accept | Ten nagłówek informuje serwer, jakie typy mediów lub formaty treści jest w stanie obsłużyć klient | Accept: text/html, application/xhtml+xml, application/xml;q=0.9, /;q=0.8 |
Authorization | Służy do przekazywania informacji uwierzytelniających od klienta do serwera. Te dane mogą być np. loginem i hasłem, tokenem uwierzytelniającym lub innym typem danych identyfikujących klienta | Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l |
Content-Type | Gdy klient wysyła dane do serwera, nagłówek Content-Type określa typ tych danych | Przykład tego nagłówka w żądaniu HTTP, które wysyła dane w formacie JSON: Content-Type: application/json |
User-Agent | Informuje serwer o rodzaju oprogramowania, które wysyła żądanie HTTP. Jest to często nazwa przeglądarki internetowej lub innego programu, który wysyła żądanie | Przykład tego nagłówka z informacją, że klient korzysta z przeglądarki Google Chrome w wersji 88 na systemie operacyjnym Windows 10. User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 |
Host | Wskazuje nazwę hosta (domeny) serwera, do którego kierowane jest żądanie. Jest to jedyny obowiązkowy nagłówek w protokole HTTP 1.1 |
Nagłówki odpowiedzi
Wysyłane przez serwer, zawierają informacje o samym zasobie oraz dodatkowe informacje, takie jak kod odpowiedzi.
| Nagłówek | Opis działania | Przykład |
|---|---|---|
Server | Zawiera informacje na temat serwera, który przetwarza żądanie HTTP | Server: Apache/2.4.41 (Unix) wskazywałoby, że serwer działa na oprogramowaniu Apache w wersji 2.4.41 na systemie operacyjnym Unix |
Set-Cookie | Jest używany przez serwer HTTP w odpowiedzi na żądanie klienta, aby ustawić lub zaktualizować ciasteczko (cookie) na stronie. Po otrzymaniu tego nagłówka, przeglądarka internetowa zapisuje ciasteczko i automatycznie dołącza je do każdego kolejnego żądania wysłanego do tego samego serwera. | Set-Cookie: sessionId=abc123; Expires=Wed, 16-Mar-2025 12:00:00 GMTW tym przykładzie: sessionId=... określa nazwę i wartość ciasteczka. Expires=... wskazuje czas wygaśnięcia ciasteczka, tutaj ustawiony na środę, 16 marca 2025 roku o godzinie 12:00:00 w czasie Greenwich Mean Time. |
Content-Type | Content-Type informuje o rodzaju treści (typie mediów) przesyłanej w treści odpowiedzi HTTP | Content-Type: application/jsonTreść tego nagłówka wskazuje, że treść przesyłana przez serwer jest w formacie JSON, co umożliwia klientowi odpowiednie przetworzenie tych danych. |
Jak już pewnie zauważyłeś/zauważyłaś, część nagłówków może istnieć zarówno w żądaniu, jak i odpowiedzi – np. Content-Type, które w żądaniu wskazuje na typ wysyłanych danych, a w odpowiedzi – o typie danych zawartych w treści odpowiedzi.
Kody odpowiedzi
Kody odpowiedzi HTTP to trzycyfrowe numery, które serwery internetowe wysyłają do przeglądarki lub innego klienta, aby poinformować go o wyniku żądania. Odpowiadają one na pytanie: „Co się stało z moim żądaniem?”. Mogą sygnalizować sukces, błąd klienta, błąd serwera lub potrzebę przekierowania do innej lokalizacji.
Czyli na przykład, jeśli spróbujemy otworzyć stronę, która nie istnieje (np. https://quality-frontiers.pl/tastronanieistnieje), serwer zwróci nam kod odpowiedzi 404 Not Found.
Kody odpowiedzi HTTP można podzielić na kilka kategorii:
- 1xx – Informacyjne: Są to informacyjne odpowiedzi, które zazwyczaj nie mają dużej wagi w kontekście przetwarzania zapytania przez klienta.
- 2xx – Sukces: Odpowiedzi z tej kategorii oznaczają, że żądanie klienta zostało pomyślnie zrealizowane przez serwer.
- 3xx – Przekierowania: Odpowiedzi te informują klienta, że zasób został przemieszczony i wymaga innej lokalizacji do dostępu.
- 4xx – Błędy klienta: Oznaczają, że żądanie zawiera błędy po stronie klienta, na przykład nieprawidłowy adres URL lub brak uprawnień.
- 5xx – Błędy serwera: Te kody wskazują na błędy po stronie serwera, co oznacza, że serwer nie jest w stanie spełnić żądania klienta z różnych powodów, na przykład awaria serwera.
Poniżej wypisałem najpopularniejsze kody odpowiedzi (lub te które po prostu warto znać):
200 OK: żądanie zostało pomyślnie zrealizowane przez serwer i klient otrzymuje oczekiwane zasoby.
404 Not Found: serwer nie może odnaleźć żądanego zasobu. To jeden z najbardziej znanych kodów błędu, gdy coś nie jest dostępne w sieci.
500 Internal Server Error: Wskazuje na błąd po stronie serwera, który powoduje nieprawidłowe przetwarzanie żądania. To ogólny błąd wewnętrzny serwera.
301 Moved Permanently: Oznacza, że zasób został przemieszczony na stałe na inną lokalizację. Przeglądarki automatycznie przekierowują użytkowników na nowy adres.
403 Forbidden: Oznacza, że serwer odrzucił żądanie ze względu na brak uprawnień dostępu. Klient nie ma dostępu do danego zasobu.
401 Unauthorized: Wymaga autoryzacji. Klient musi przesłać odpowiednie dane uwierzytelniające, aby uzyskać dostęp do zasobu.Treść odpowiedzi
Treść odpowiedzi HTTP to dane wysyłane z serwera do klienta w ramach odpowiedzi HTTP, czyli zawartość, którą klient zażądał od serwera. Może zawierać różne typy danych, takie jak HTML, XML, JSON, obrazy, filmy lub zwykły tekst.
W przykładzie na początku tego artykułu, treścią odpowiedzi do naszego żądania był kod HTML strony, którą chcieliśmy wyświetlić w przeglądarce.
Weźmy inny przykład – niech to będzie odpowiedź w formacie JSON. W tym celu użyjmy „fejkowego” REST API zwracającego dane z uniwersum Star Wars. Wyobraźmy sobie, że chcemy otrzymać informacje dotyczące np. Luke’a Skywalkera. Wysyłamy w tym celu request GET pod https://swapi.dev/api/people/1 i otrzymujemy treść odpowiedzi w formacie JSON:
{
"name": "Luke Skywalker",
"height": "172",
"mass": "77",
"hair_color": "blond"
}Nagłówek HTTP dla tej odpowiedzi będzie wyglądać tak:
Content-Type: application/jsonHTTP w praktyce
Pamiętasz grafikę z początku artykułu? Sprawdźmy, jak wygląda komunikacja HTTP na konkretnym przykładzie, czyli kiedy chcemy wejść na stronę naszego bloga w przeglądarce:
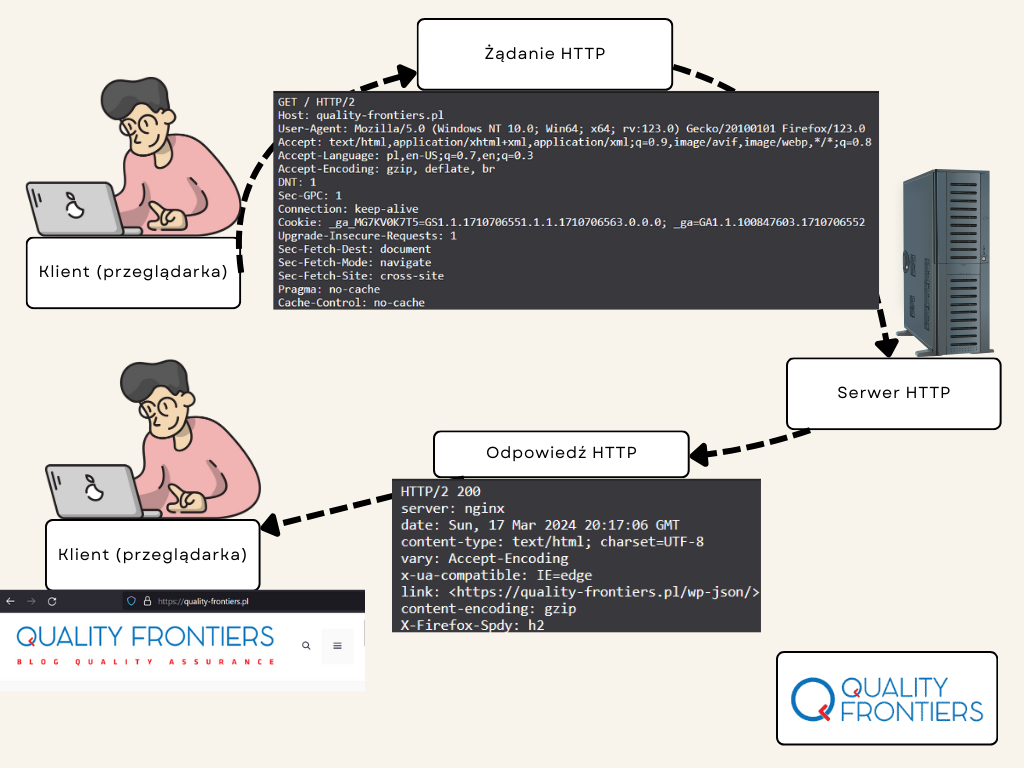
Wykorzystując wiedzę z poprzednich akapitów, spróbujmy opisać żądanie i odpowiedź HTTP – zacznijmy od żądania:
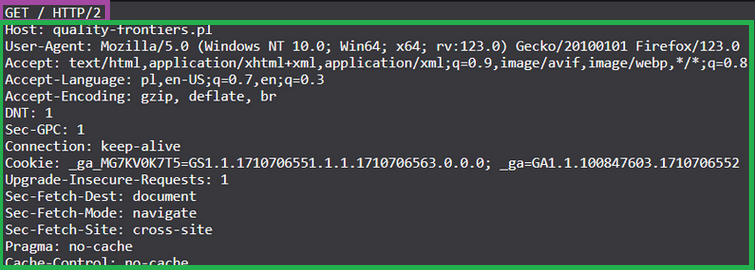
Kolorem fioletowym zaznaczyłem linijkę żądania. Zawiera ona:
- metodę w tym przypadku
GET– czyli pobranie danych w serwera - adres URL:
/oznacza stronę główną - wersję protokołu – tutaj jest to
HTTP/2
Poniżej linijki żądania, znajdują się (oznaczone kolorem zielonym) nagłówki żądania. Rozszyfrujmy kilka z nich: nagłówek User-Agent mówi nam, że żądanie HTTP zostało wysłane przez przeglądarkę Firefox w wersji 123.0, działającą na systemie Windows 10. Nagłówek HTTP Accept informuje serwer o preferencjach klienta odnośnie akceptowanych typów treści – w tym przypadku HTML. Nagłówek Cookie wysyła ciasteczko do serwera.
W odpowiedzi HTTP, pierwszą linijką jest status odpowiedzi (kolor niebieski). Kod 200 oznacza, że nasze żądanie zostało pomyślnie zrealizowane przez serwer i że klient (nasza przeglądarka) otrzymał odpowiedź zawierającą żądane zasoby – czyli kod HTML strony WWW którą chcieliśmy otworzyć.
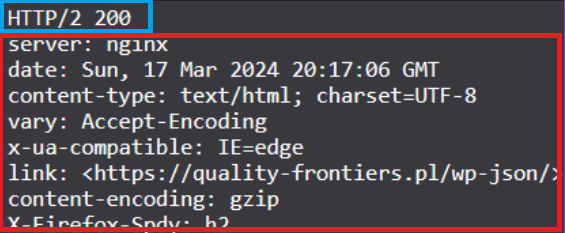
Następnie, odpowiedź zawiera nagłówki odpowiedzi (kolor czerwony). Z nich możemy dowiedzieć się np. jaka była data i godzina w momencie otrzymania odpowiedzi z serwera, jaki typ danych zwrócił serwer (kod HTML), a także o rodzaju serwera który obsłużył tę odpowiedź (nagłówek server).
Serwer zwrócił nam także treść odpowiedzi (eng. response body) czyli w tym przypadku kod HTML strony WWW:
<!DOCTYPE html>
<html lang="pl-PL">
<head>
<meta charset="UTF-8">
<title>Quality Frontiers - Blog ekspercki QA</title>
(...)Warto wiedzieć!
„Wiem czy jest HTTP, ale czym w takim razie jest HTTPS?”
HTTPS (Hyper Text Transfer Protocol Secure) to zabezpieczona wersja protokołu HTTP, która używa protokołu TLS lub SSL do szyfrowania komunikacji między przeglądarką internetową a serwerem. Przesyłanie wrażliwych informacji powinno odbywać się przez właśnie przez HTTPS.
HTTP jest bezstanowe
Protokół HTTP jest uznawany za bezstanowy (eng: stateless). Oznacza to, że każde żądanie wysyłane przez klienta i każda odpowiedź zwracana przez serwer są niezależne od siebie i nie mają żadnej pamięci dotyczącej poprzednich zapytań ani odpowiedzi. Innymi słowy, każde zapytanie, które klient wysyła do serwera, zawiera wszystkie niezbędne informacje potrzebne do wykonania operacji, a serwer zwraca odpowiedź, nie zachowując żadnych danych o poprzednich zapytaniach i nie mając świadomości, czy klient już wcześniej wykonywał jakieś akcje.
W celu zachowania stanu między różnymi zapytaniami, na przykład podczas sesji użytkownika, aplikacje internetowe mogą korzystać z mechanizmów takich jak ciasteczka (cookies), local storage lub sesje.
HTTP 1.1, HTTP 2.0 – co to znaczy?
W dużym skrócie – HTTP 1.1 to starsza wersja protokołu HTTP. Obecnie coraz częściej można spotkać nowszą wersję oznaczoną jako 2.0. Zmiany wprowadzone w HTTP 2.0 obejmują głównie poprawę wydajności, elastyczność i wydajniejsze zarządzanie połączeniami sieciowymi.
URL czy URI?
Prawie każdy zna termin „URL” (Uniform Resource Locator). Najczęściej w ten sposób określamy adres, który wpisujemy w pasek adresu w przeglądarce, np https://quality-frontiers.pl.
W czym problem? W tym, że w wielu specyfikacjach nie istnieje takie pojęcie jak URL, a URI (Uniform Resource Locator). Technicznie rzecz biorąc, URL jest rodzajem URI, który definiuje konkretną lokalizację zasobu w Internecie. URL identyfikuje zarówno lokalizację zasobu, jak i protokół komunikacyjny, który należy użyć do uzyskania dostępu do tego zasobu (np. HTTP lub HTTPS).
W praktyce, wiele osób używa terminów „URL” i „URI” zamiennie i nie ma z tym problemów.
To już koniec! Jeśli udało Ci się dojść do tego miejsca, możesz powiedzieć że znasz już podstawy komunikacji HTTP 🙂 to solidny fundament do dalszej nauki. Naturalną kontynuacją tego tematu są testy API (kurs w przygotowaniu).
Dobra robota! Temat niby znany, a jednak przedstawiłeś go w świeży sposób. Gratulacje!