
Do zrozumienia poniższego tekstu wymagana jest znajomość podstaw protokołu HTTP, w szczególności metod HTTP i kodów odpowiedzi. Jeśli potrzebujesz przypomnieć sobie te zagadnienia, zachęcam Cię do zapoznania się z naszym wstępem do HTTP.
Na początek – czym jest API?
API, czyli Application Programming Interface (Interfejs Programowania Aplikacji), to zestaw reguł i narzędzi, które umożliwiają różnym programom komunikowanie się ze sobą. API udostępnia jasno zdefiniowane funkcje, które można wywołać, aby uzyskać dane lub wykonać określone operacje, co pozwala na interakcję między różnymi aplikacjami.
Mechanizm działania API często porównuje się do kelnera w restauracji, który przekazuje zamówienia między klientem a kuchnią. Wyobraź sobie następującą sytuację: wchodzisz do restauracji, zamawiasz jedzenie, kelner przyjmuje zamówienie, przekazuje je do kuchni, kuchnia przygotowuje jedzenie, kelner odbiera je i przynosi Tobie. Proces ten można zobrazować tak jak na poniższej grafice:
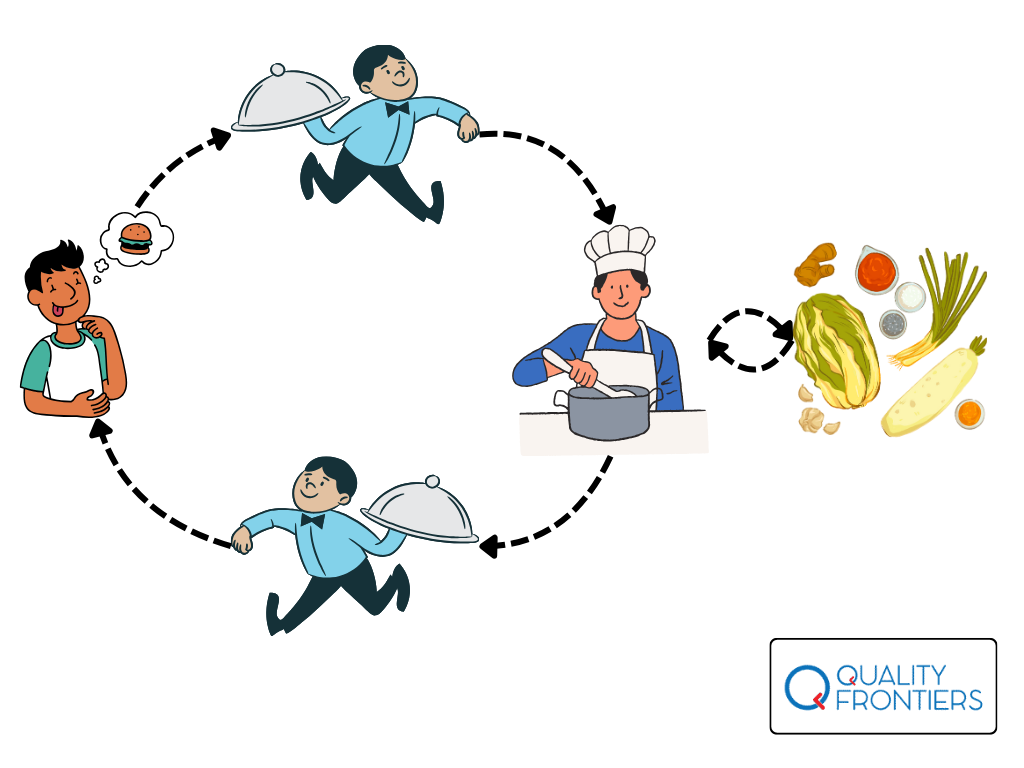
Co to ma do API? Wyobraź sobie API jako menu w restauracji. Menu pokazuje różne dania (funkcje), które możesz zamówić, oraz opis tego, co dostaniesz. Kiedy wybierasz danie (wysyłasz żądanie), kuchnia (serwer) przygotowuje je i podaje Ci (odpowiedź), korzystając z dostępnych składników (baza danych). Kiedy zamawiasz danie X, nie musisz znać dokładnego przepisu na to danie – mówisz jedynie, jakie danie chcesz otrzymać i nie interesuje Cię jak dokładnie będzie ono przyrządzane. Zależy Ci jedynie na efekcie, czyli na otrzymaniu konkretnej potrawy.
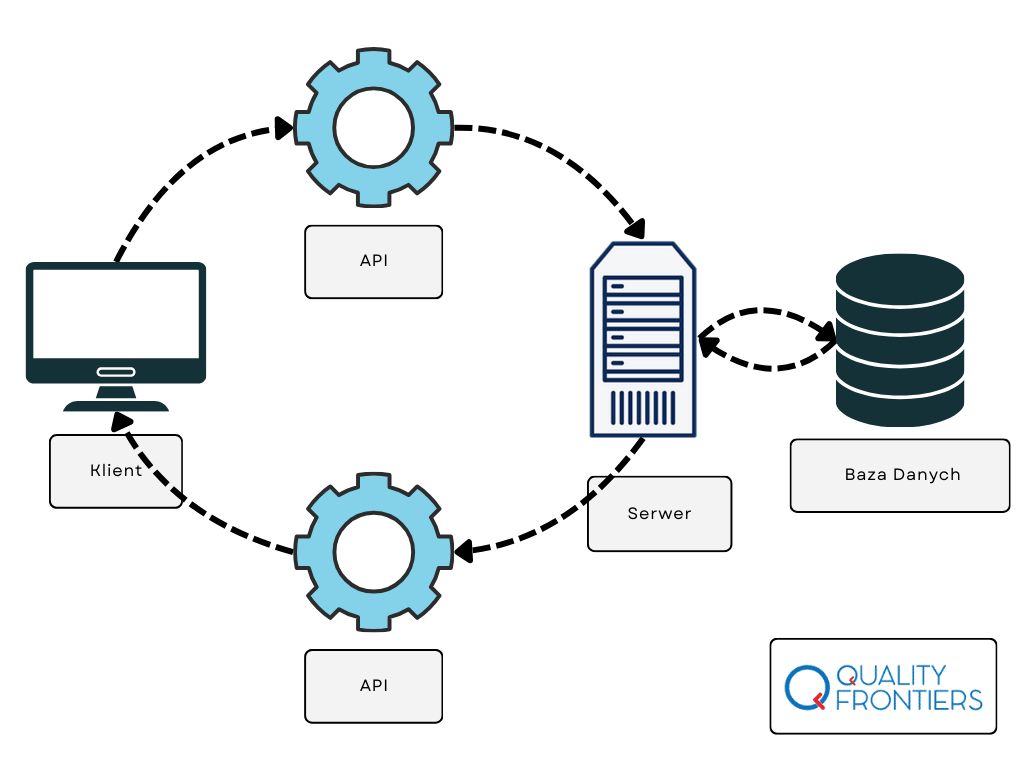
Tak właśnie działa API – pozwala aplikacjom komunikować się ze sobą, przekazując żądania i odpowiedzi. Użytkownik API nie musi znać wewnętrznych szczegółów implementacji na serwerze, tak jak klient restauracji nie musi znać dokładnych przepisów, żeby zamówić jedzenie. Korzystając z API nie musimy wiedzieć, jak serwer przetwarza dane, jakie algorytmy są do tego wykorzystywane, ani jakie operacje są wykonywane po stronie serwera. Nie musimy nawet zdawać sobie sprawy, na jakich technologiach (np. jaki język programowania, framework, czy serwer) opiera się API ani jak zarządzana jest infrastruktura serwerowa. Ważne jest tylko, że API dostarcza dokładnie to, co zostało zamówione, zgodnie z jego specyfikacją.
Podsumowując, API działa jak „czarna skrzynka” – dostarcza wymaganych danych lub usług, ale ukrywa przed użytkownikiem złożoność i szczegóły swojej implementacji, dzięki czemu korzystanie z niego jest proste i intuicyjne.
A czym jest REST API?
REST (Representational State Transfer) to popularny zbiór reguł (nie specyfikacja!) wykorzystywanych w tworzeniu interfejsów API, które umożliwiają komunikację między systemami przez Internet. API, które podąża za tymi standardami nazywane jest RESTful API.
REST działa na zasadzie prostych zapytań HTTP (takich jak GET, POST, PUT, DELETE), które pozwalają na uzyskiwanie, wysyłanie, aktualizowanie lub usuwanie danych na serwerze.
Zasoby
Idąc dalej za naszym przykładem kucharza i kuchni, wyobraź sobie aplikację takiej restauracji, która ma przyjmować zamówienia i trzymać dane na temat np. dostępnych potraw, składników, pracowników i klientów.
W powyższym przykładzie, potrawy, składniki, pracownicy i klienci to tak zwane zasoby. W specyfikacji REST API zasób to dowolny obiekt, dane lub jednostka, którą można jednoznacznie zidentyfikować i zarządzać nią za pomocą operacji HTTP (takich jak GET, POST, PUT, DELETE). Zasób jest podstawowym elementem, na którym opiera się architektura RESTful.
Zasoby muszą spełniać pewne warunki:
- nazwa zasobu musi być rzeczownikiem, najczęściej w języku angielskim i w liczbie mnogiej
- RESTful API organizuje zasoby w unikalne adresy URL, a każdy zasób ma unikalny identyfikator (np. numer ID).
- może mieć różne reprezentacje, najczęściej w formacie JSON, ale dopuszczalne jest także użycie XML, lub HTML
Tak więc w naszym przykładowym REST API, pracownicy będą reprezentowani jako https://api.example.com/employees, klienci jako https://api.example.com/clients, itd.
Przyjrzyjmy się, jak może wyglądać przykładowa reprezentacja zasobu /clients. Oto co otrzymamy, kiedy wyślemy request GET pod zmyślony URL https://api.example.com/clients:
[
{
"id": 1,
"name": "Zenek Kowalski",
"email": "zenek.kowalski@example.com",
"phone": "+48 123 456 789"
},
{
"id": 2,
"name": "Anna Nowak",
"email": "anna.nowak@example.com",
"phone": "+48 987 654 321"
},
{
"id": 3,
"name": "Janusz Wiśniewski",
"email": "janusz.wisniewski@example.com",
"phone": "+48 555 666 777"
}
]Widzimy, że nasze API zwraca nam trzech klientów. Każdy z nich ma swój unikalny nr ID, a także imię i nazwisko, email i nr telefonu.
Jeśli będziemy chcieli pobrać dane dotyczące klienta o numerze ID równym jeden, wyślemy request pod adres https://api.example.com/clients/1. Wtedy otrzymamy dane tylko jednego klienta – tego z ID = 1:
[
{
"id": 1,
"name": "Zenek Kowalski",
"email": "zenek.kowalski@example.com",
"phone": "+48 123 456 789"
}
]Endpointy
Tutaj dochodzimy do definicji endpointu. Endpoint to po prostu adres URL, pod którym dostępny jest dany zasób. Rozbijmy na czynniki pierwsze endpoint z poprzedniego przykładu:

https– protokół: nieszyfrowany HTTP lub szyfrowany HTTPSexample-api.pl– nazwa domeny/api– ścieżka bazowa, główna ścieżka dostępu do wszystkich zasobów API- /
v1– wersja API. Określa wersję API, w tym przypadku wersję 1. Wersjonowanie pozwala na wprowadzanie zmian w API bez zakłócania działania istniejących klientów, którzy mogą nadal korzystać ze starszych wersji /clients– zasób, w tym przypadku grupa klientów/1– Identyfikator zasobu: W tym przypadku identyfikuje klienta o ID 1.
Path Variables
Path variable to konkretny fragment adresu URL, który umożliwia zidentyfikowanie lub odwołanie się do konkretnego zasobu. Rozważmy endpoint /clients/{id}. Tutaj {id} to tak zwany path parameter, który reprezentuje zmienną część ścieżki. Z kolei użyty wcześniej /clients/1 to path variable, ponieważ wskazuje konkretny zasób.
Query Parameter
Wiemy już, że jeśli w naszych poprzednich przykładach wyślemy request pod /clients, to w odpowiedzi dostaniemy dane wszystkich klientów. Jeśli dodamy do tego ID klienta, czyli nasz endpoint będzie kończył się /clients/1, to dostaniemy dane klienta o ID = 1. Co w przypadku, gdy chcielibyśmy np. wyszukać wszystkich klientów, którzy mają więcej niż 25 lat? Lub wszystkich klientów o imieniu Zenek? Najlepiej, gdybyśmy dostali dane tych klientów posortowane w kolejności alfabetycznej. Czy jest to możliwe?
Tak. W REST API istnieje możliwość wyszukiwania, filtrowania i sortowania danych za pomocą tak zwanych query parameters.
Query params są umieszczane na końcu adresu URL, po znaku zapytania. Poniżej znajduje się przykład query param, który wyszuka klientów mających na imię Zenek:
https://example-api.pl/api/v1/clients?name=ZenekA tak wygląda przykład query param, gdzie również szukamy wszystkich klientów o imieniu Zenek, ale także określamy ich wiek na wyższy niż 25 lat. Dodatkowo, sortujemy wyniki rosnąco (ascending).
https://api.example.com/clients?name=Zenek&age>25&sort=ascBezpieczeństwo
Na koniec sprawy najważniejsze, czyli bezpieczeństwo REST API.
Pierwszą linią obrony REST API jest uwierzytelnianie (authentication) i autoryzacja (authorization). Na rekrutacjach często dostaje się pytanie czym różni się jedno od drugiego 🙂
Uwierzytelnianie polega na weryfikacji tożsamości użytkownika lub systemu, który próbuje uzyskać dostęp do API. Typowe mechanizmy uwierzytelniania obejmują między innymi:
- Tokeny dostępu (np. JWT),
- API Key (klucze dostępu),
- Basic Auth (uwierzytelnianie podstawowe, z użyciem nazwy użytkownika i hasła).
Autoryzacja jest procesem sprawdzania, czy uwierzytelniony użytkownik ma prawo dostępu do zasobów lub wykonywania określonych operacji. Nawet po poprawnym uwierzytelnieniu użytkownika należy sprawdzić, czy ma on odpowiednie uprawnienia do działania, np. odczytu, zapisu, edycji lub usuwania danych.
Kolejną ważną kwestią jest użycie HTTPS. Kiedy dane są przesyłane między klientem a serwerem, muszą być szyfrowane, aby zapewnić ochronę przed podsłuchiwaniem i modyfikacjami. Dzięki HTTPS, dane są bezpieczne podczas transmisji, co jest szczególnie istotne, gdy mówimy o danych wrażliwych.